2025年春节期间,国产的DeepSeek系列大模型火爆出圈,引发全球广泛关注DeepSeek公司推出的DeepSeek App更成为全球增速最快的AI应用,仅上线18天,日活用户就达到1500万如今,DeepSeek以现象级的姿态席卷整个业界和社交网络,几乎无人不知。

这场现象级爆发根源于DeepSeek的强大技术突破,DeepSeek-R1模型以不到OpenAI 1/20的成本实现了推理速度较行业平均水平提升20倍、能耗效率达70倍以上的突破这种“低成本高性能”的特性直接冲击了传统的AI观念。

不过也正是因为过于火爆,DeepSeek官网和App提供的在线对话服务总是报错,而其他云服务商提供的基于DeepSeek大模型的服务不仅要收费(部分免费的除外),还需要联网在线使用,用起来不那么方便
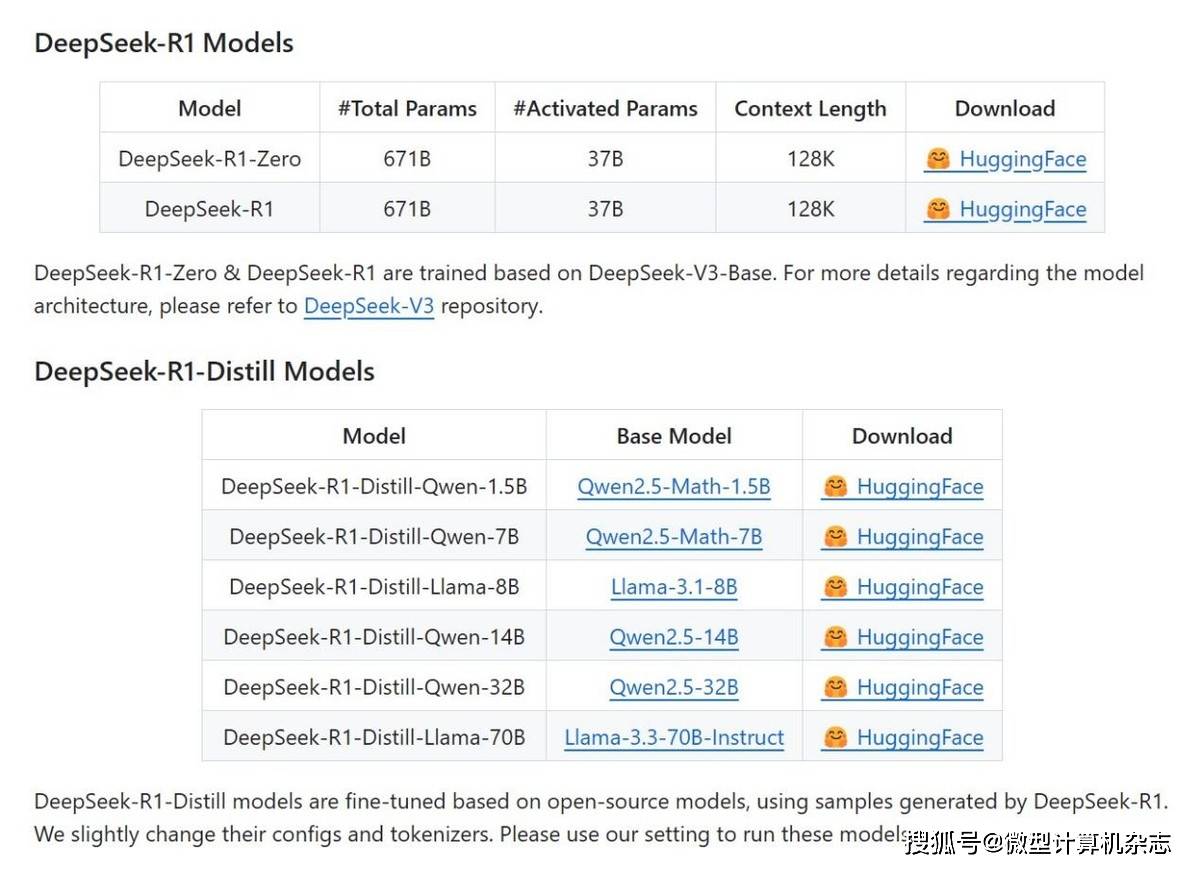
▲DeepSeek-R1系列大模型都是开源的,官方提供了免费的下载渠道另外,我们知道DeepSeek-R1系列大模型是开源的,任何人都可以部署在本地使用,那么我们怎样才能将它部署在笔记本上,随时随地无限制使用呢?请跟着我们的介绍一步一步来看。
需要说明的是,在本地部署LLM大模型对笔记本的内存、显存的要求极高,根据大模型参数规模的不同,我们的笔记本至少要配备16GB内存才能加载70亿参数(7B)的主流大模型另外,为了更流畅地运行本地大模型,还离不开芯片平台对大模型的支持,比如本次DeepSeek爆火出圈的时候,AMD率先宣布全力支持DeepSeek,如今在AMD锐龙AI笔记本上,我们也能轻松部署运行DeepSeek-R1系列大模型。
具体操作起来,我们主要通过LM Studio软件在AMD锐龙AI笔记本上本地部署、体验DeepSeek-R1精简版推理模型我们以一款16英寸、搭载AMD锐龙AI 9 HX 370处理器、Radeon 890M显卡的轻薄本为例,教大家部署DeepSeek-R1精简版推理模型。
1、首先是做好准备工作,安装AMD Adrenalin 25.1.1或更新版的显卡驱动。这个直接去AMD官网即可下载。
2、第二步是在电脑上安装LM Studio的AMD锐龙AI专版软件具体的下载地址是lmstudio.ai/ryzenai3、安装好了之后启动LM Studio软件,跳过引导屏幕,之后点软件右下角的设置图标,将软件语言设置为中文,这样方便使用。
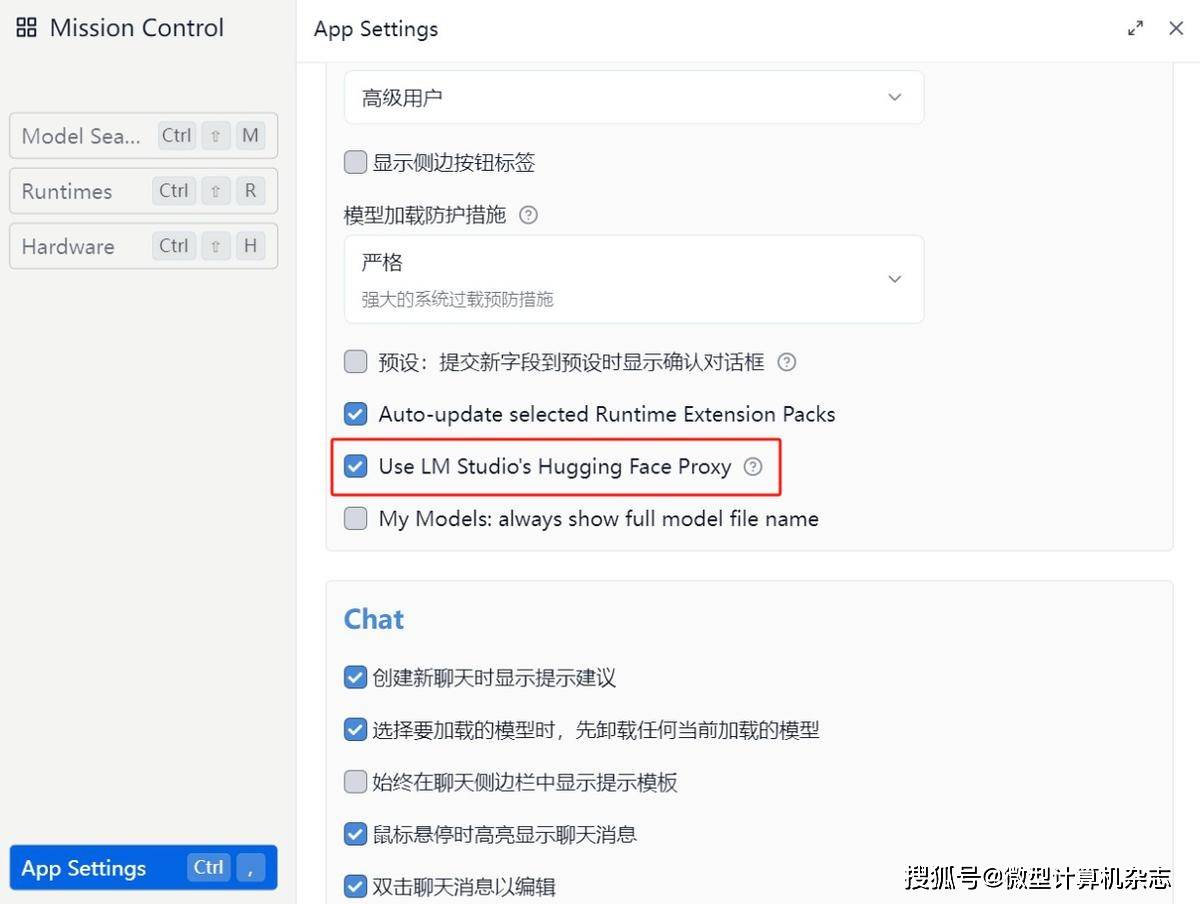
4、随后在软件的设置中勾选软件自身提供的网络优化设置,这一步很重要,否则可能无法下载大模型。
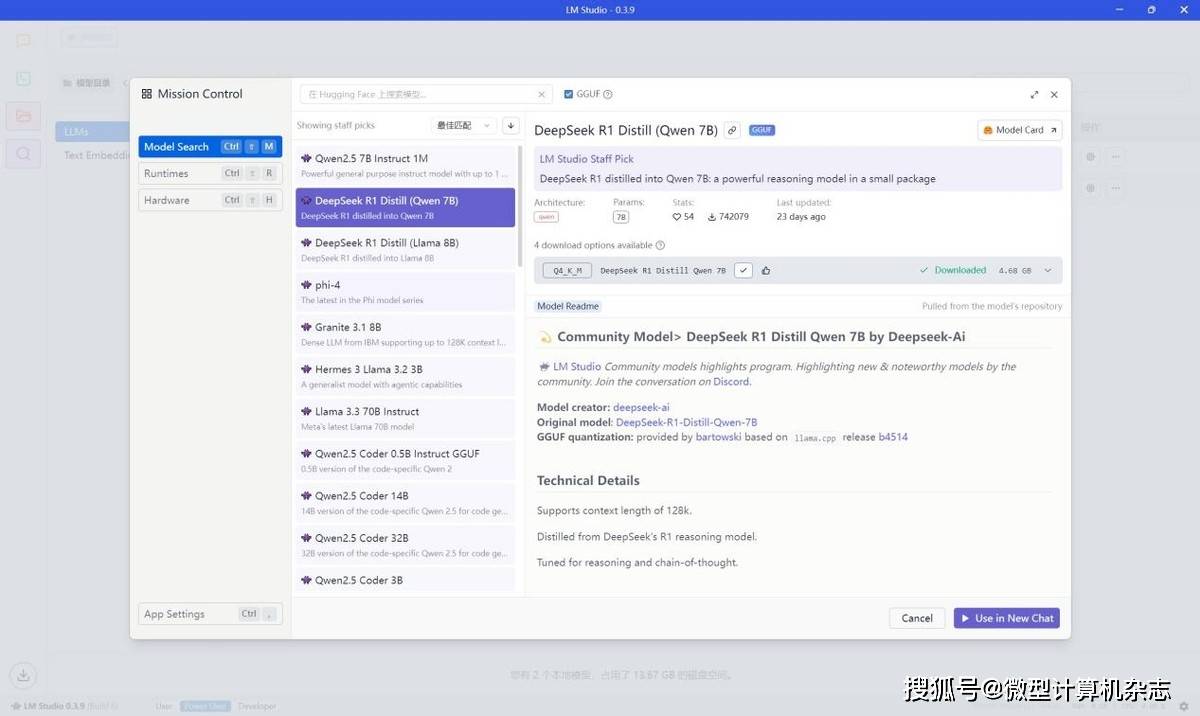
5、点击“发现”(搜索图标)标签页,进入大模型下载页面,找到需要部署的DeepSeek-R1系列大模型,我们推荐使用DeepSeek-R1-Distill-Qwen-7B-GGUF和DeepSeek-R1-Distill-Qwen-14B-GGUF,其中还有一个最小参数规模的DeepSeek-R1-Distill-Qwen-1.5B-GGUF,它适用于一些配置较低、性能较差的机型,而AMD锐龙AI笔记本(包括锐龙7040系列笔记本)只要内存规模满足需求,都能流畅运行7B规模的大模型,用不着使用1.5B规模的模型。
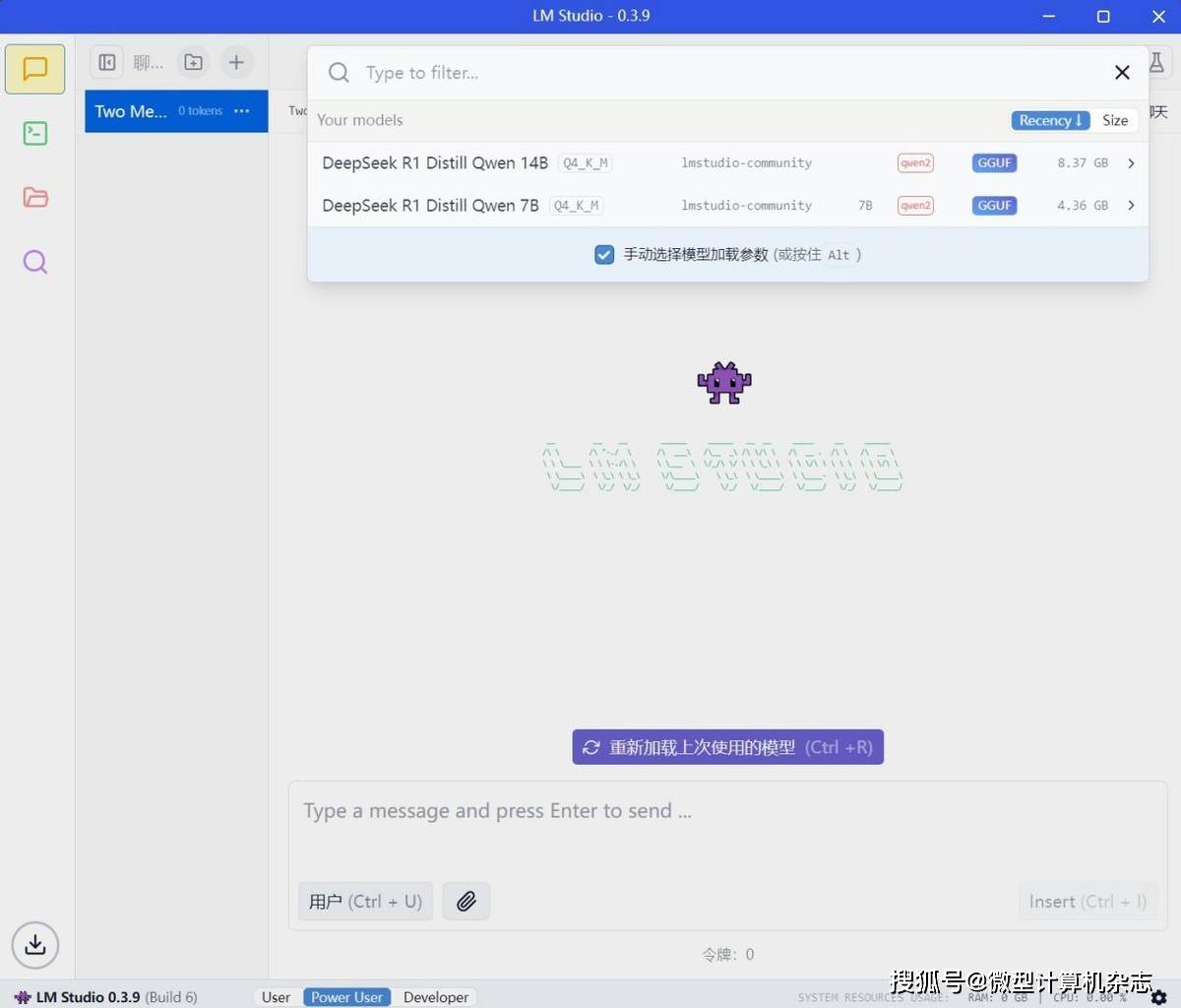
6、将大模型下载完成后返回聊天选项页,从下拉菜单中选择对应的模型,并确保勾选“手动选择参数”选项。在“GPU卸载”中将滑块移到最大值。
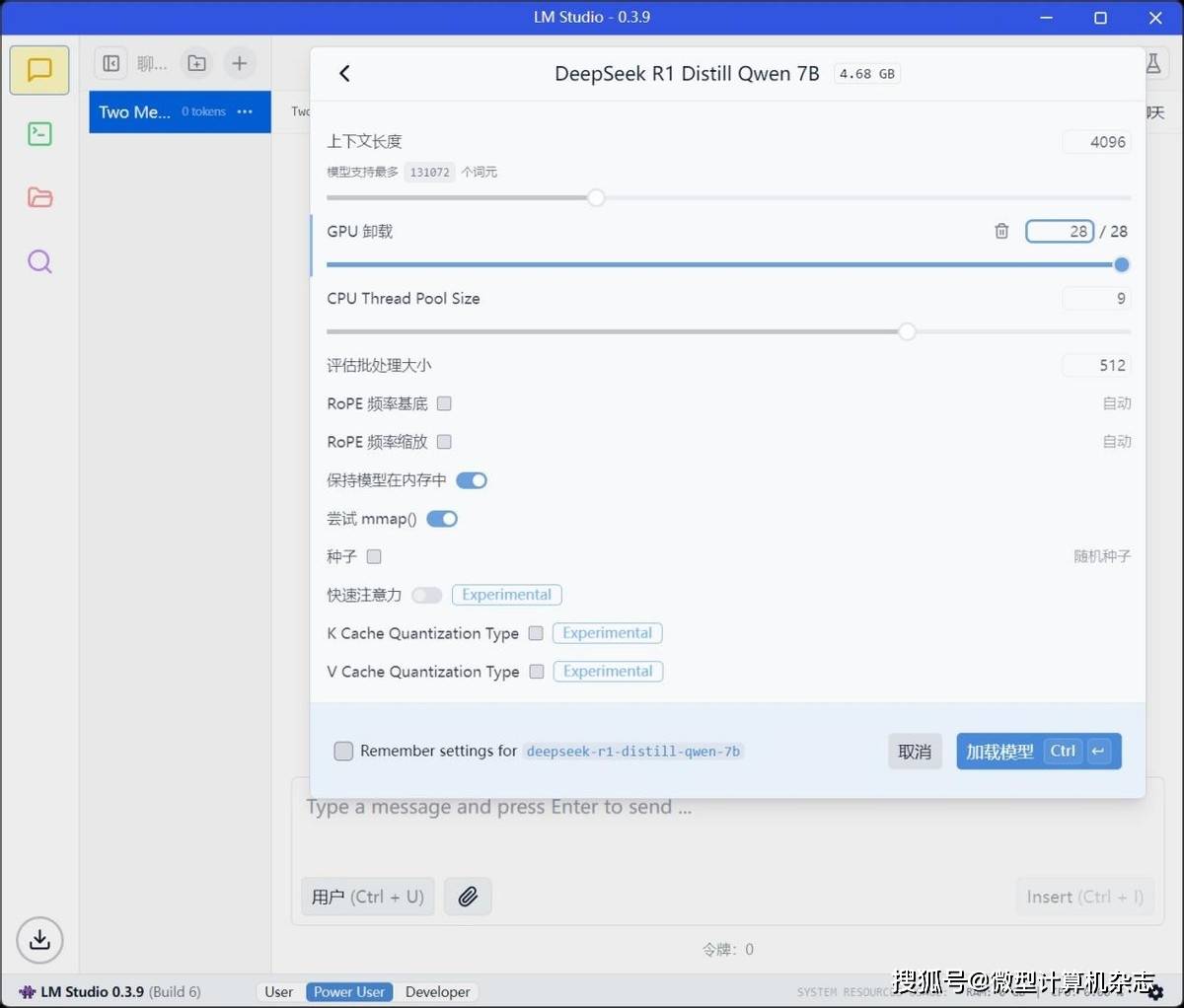
7、点击“加载模型”(model load),就可以在本地体验DeepSeek-R1系列推理模型了!大模型的性能和体积主要看参数规模,超大规模的大模型在部署和运行时往往需要极高的内存容量和显存容量,因此大家主要根据笔记本的实际配置来选择对应的大模型即可。
AMD也公布了搭载锐龙7040系列及以上处理器的笔记本最大支持DeepSeek-R1系列大模型的信息,大家可以根据自身的实际情况来选择
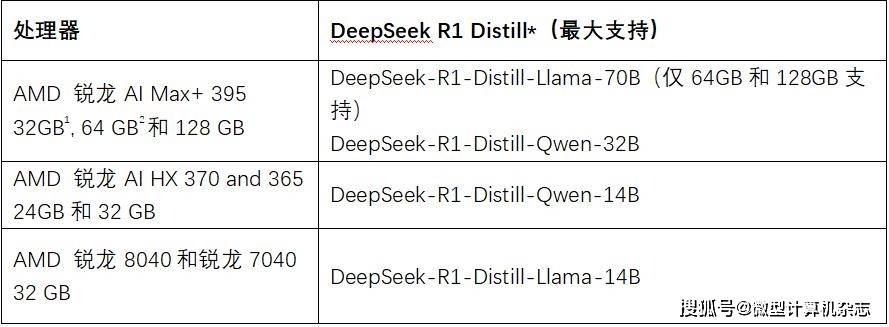
根据AMD公布的信息,旗舰级别的锐龙AI Max+ 395处理器搭配64GB或者128GB内存最高可以支持DeepSeek-R1-Distill-Llama-70B,其中64GB内存的话需要将可变显存设置为高,如果搭配32GB内存,那么可变显存需要自定义为24GB就能支持到DeepSeek-R1-Distill-Qwen-32B。
如果是锐龙AI HX 370、锐龙AI 365处理器,搭配24GB或者32GB内存最高可以支持到DeepSeek-R1-Distill-Qwen-14B锐龙7040/8040系列笔记本搭配32GB内存最高也可支持到DeepSeek-R1-Distill-Qwen-14B。
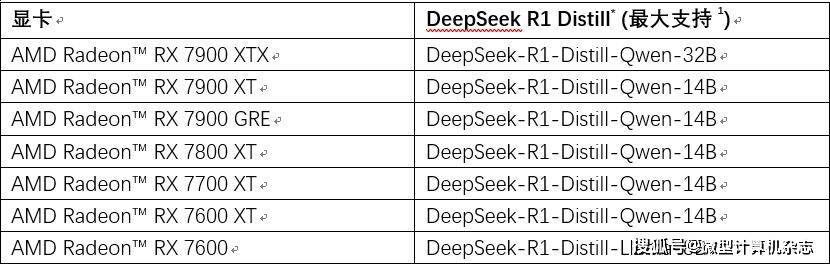
值得一提的是,AMD Radeon RX 7000系列桌面显卡也能很好地支持DeepSeek-R1系列大模型我们本次在一款16英寸,搭载AMD锐龙AI 9 HX 370处理器、Radeon 890M显卡以及32GB LPDDR5X 7500双通道内存的轻薄本上部署了。
DeepSeek-R1-Distill-Qwen-7B和DeepSeek-R1-Distill-Qwen-14B大模型,来看看实际效果吧!
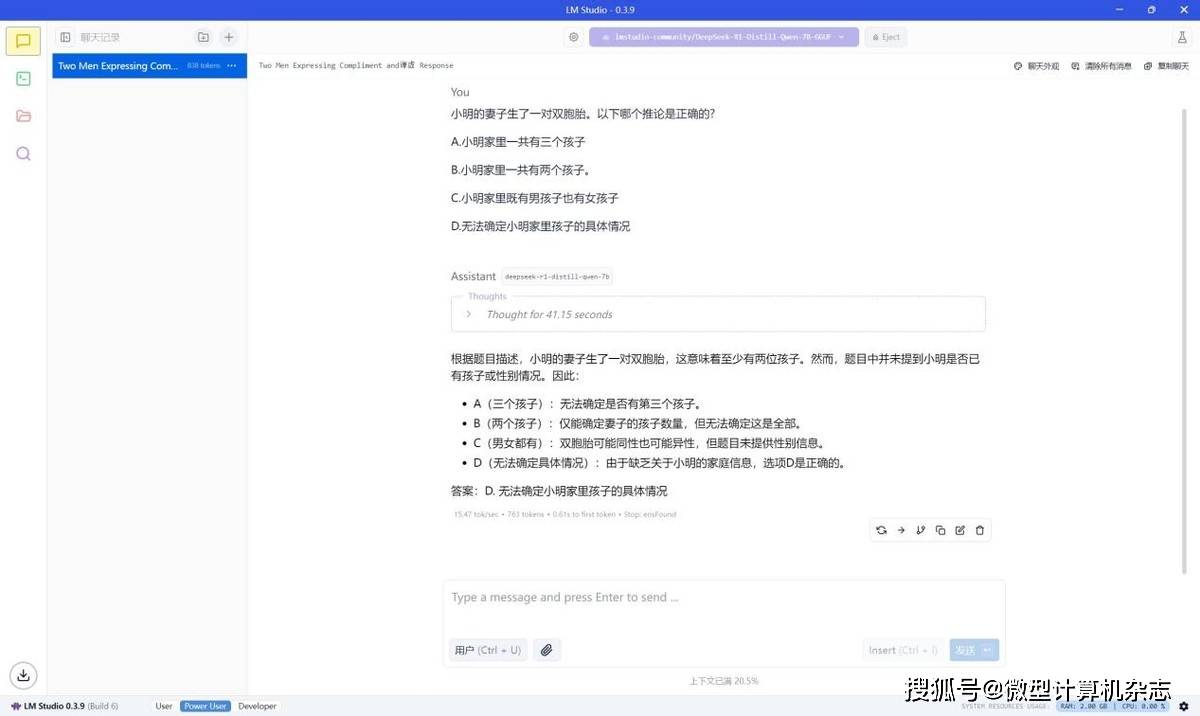
在默认的0.5GB显存设置下,锐龙AI 9 HX 370平台能够非常流畅地运行DeepSeek-R1-Distill-Qwen-7B大模型,我们随便问一个推理问题,它的推理速度达到15.47 tokens/s,完全可堪大用。
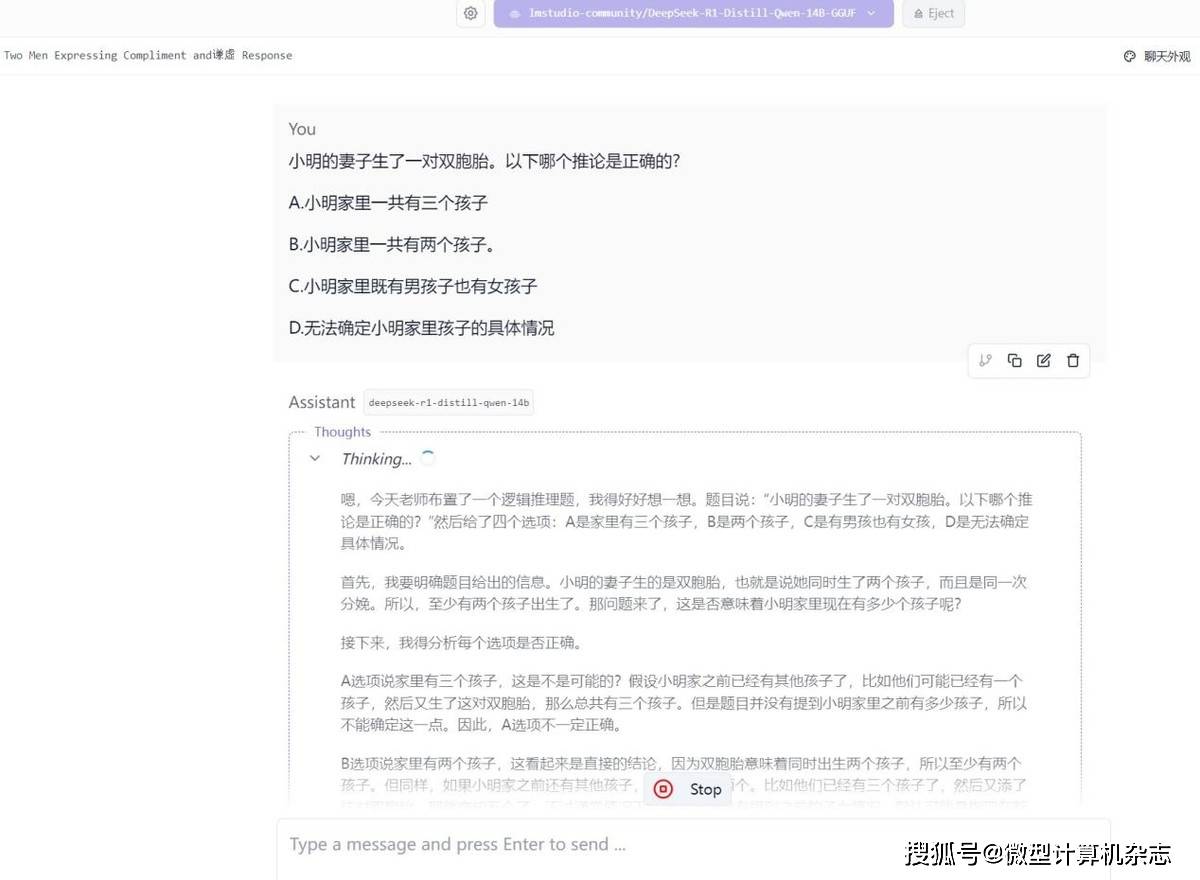
正如使用在线的DeepSeek服务一样,本地部署的大模型同样会显示它的思考过程。

在默认的0.5GB显存设置下,锐龙AI 9 HX 370平台运行DeepSeek-R1-Distill-Qwen-14B大模型也比较流畅,它的推理速度降低到7.37 tokens/s,速度虽然相比70亿规模时稍微慢点,但是日常使用也没问题,毕竟140亿参数规模的大模型在准确性和创作性上更出色。
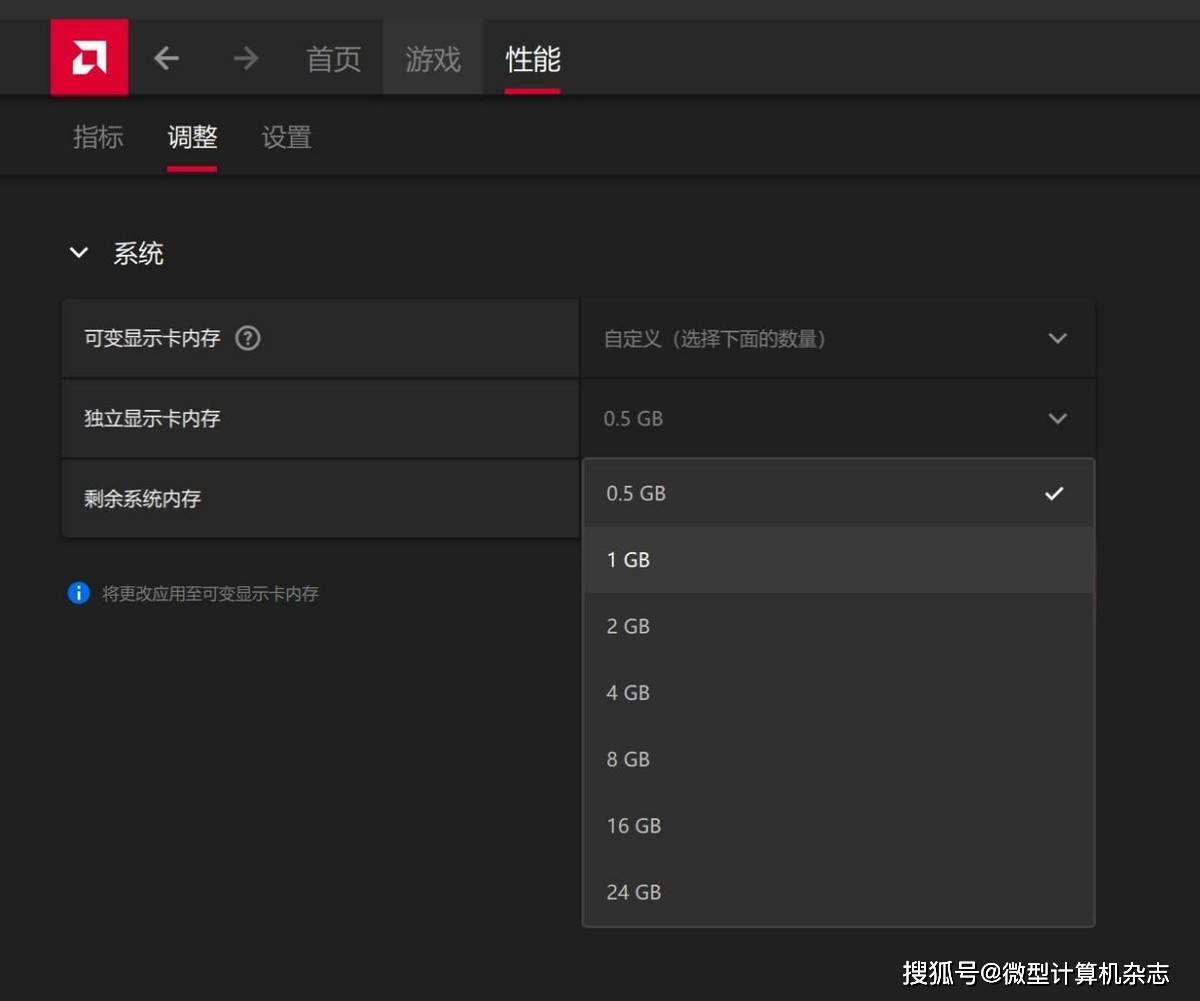
别忘了AMD锐龙AI 300系列处理器还支持调整显卡的显存,我们将显存调整至16GB,保留16GB内存,来看看在这种情况下运行DeepSeek-R1系列大模型的速度如何。
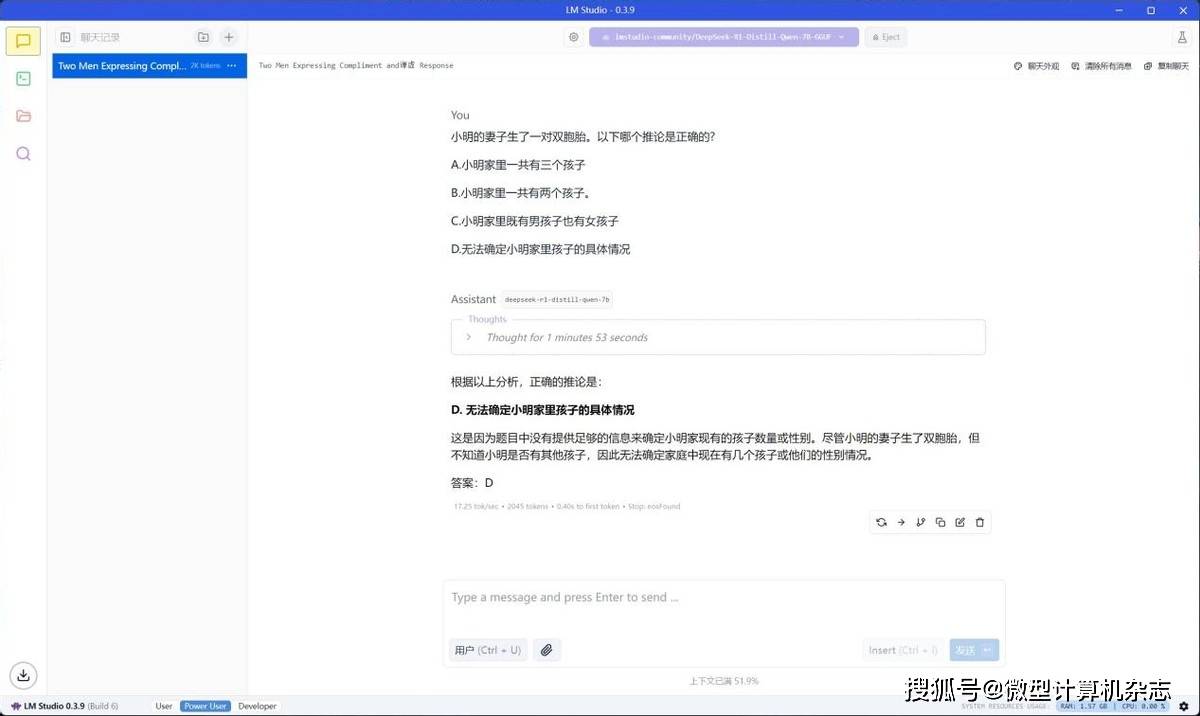
在16GB显存之下,这台机器运行DeepSeek-R1-Distill-Qwen-7B大模型的速度确实有提升,从默认显存设置下的15.47 tokens/s提升到17.25 tokens/s,提升幅度达到11.5%。
实际使用感受是它更流畅了,回答问题的速度更快一些
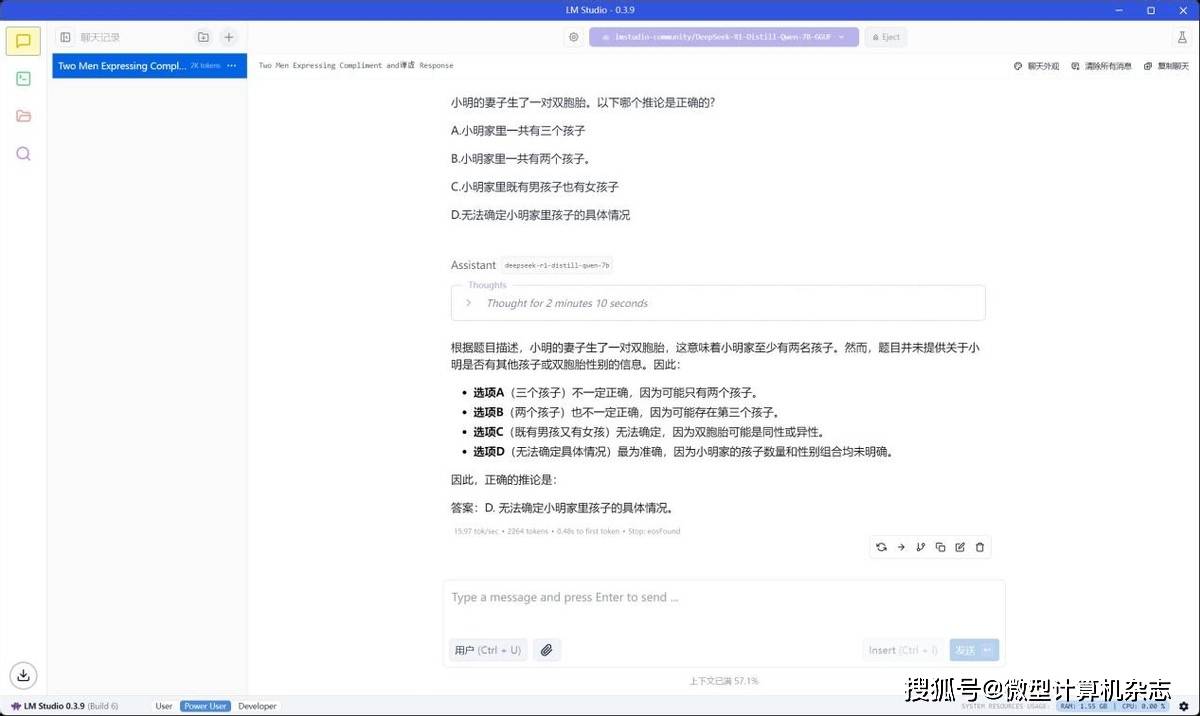
即便是在使用电池的情况下,这台机器在16GB显存的设置下运行DeepSeek-R1-Distill-Qwen-7B大模型的速度也达到15.97 tokens/s,甚至比默认显存设置(插电)的速度还快,也就是说出差时在飞机客舱之类的离线离电环境中,我们也能流畅使用DeepSeek。

在16GB显存之下,这台机器运行DeepSeek-R1-Distill-Qwen-14B大模型的速度提升到8.8 tokens/s,推理回答的速度更快一些部署好DeepSeek-R1系列大模型之后,我们就可以简单来整活儿,感受一下本地DeepSeek-R1系列大模型的魅力。
可以看到,有了DeepSeek-R1系列大模型,大家在一台轻薄本上就可以享受本地大模型的魅力,无论是优雅地骂人还是进行翻译、撰写文档或者做公务员考试的题,都不在话下另外在进阶一下,LM Studio软件还提供了本地服务器的功能,在它的设置中可以直接开启与OpenAI兼容的本地服务器,之后在本地或局域网中的其他用户也可以通过端口连接来使用部署在这台机器上的大模型,这对团队、寝室、班级或者小微企业来讲很有帮助。
比如Chatbox AI这个软件就提供了LM Studio的API接入服务,我们在电脑上安装这款软件之后只需要简单的设置使用LM Studio的API,即可在Chatbox AI中使用LM Studio部署的DeepSeek-R1系列大模型。
好了,今天的教程就到这里。在AMD锐龙AI笔记本上部署DeepSeek-R1系列大模型是不是毫无门槛?你也来试试吧!返回搜狐,查看更多
