激活函数通过引入非线性,使神经网络能够学习复杂的关系和模式,在神经网络中发挥着至关重要的作用。以下是一些常用的激活函数:
Sigmoid 函数 (Logistic):
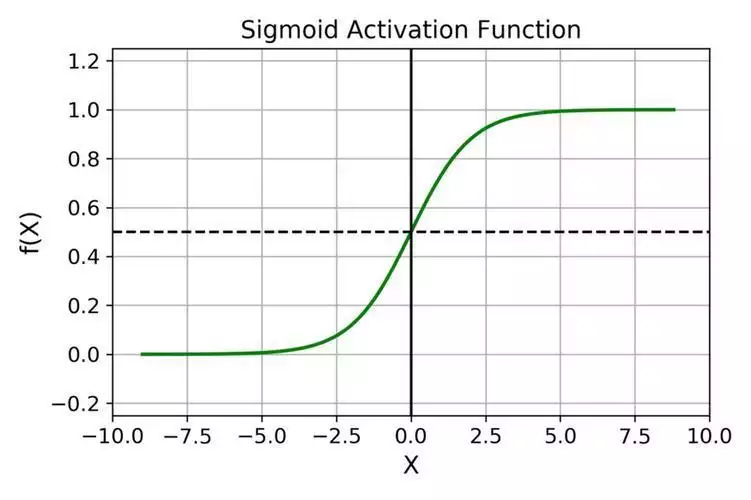
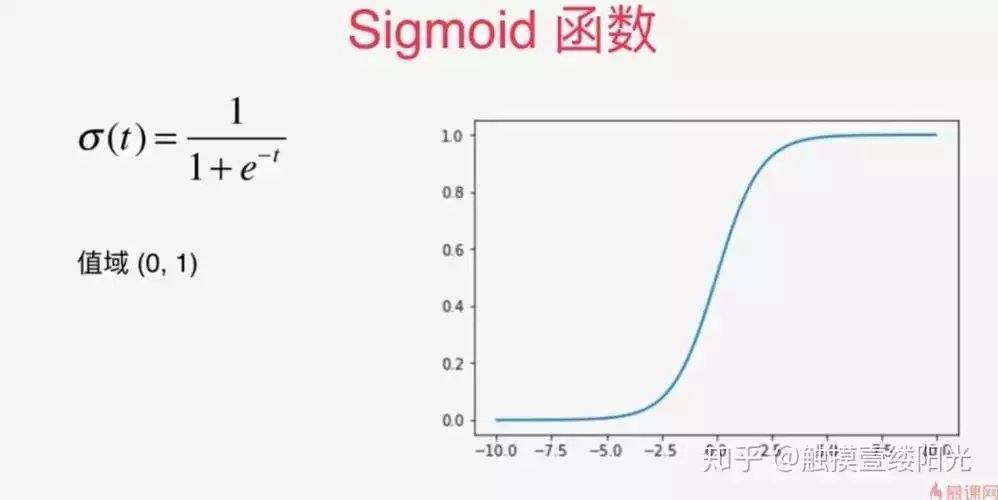
sigmoid 函数具有 S 形曲线,由以下公式定义:sigma(x) = 1/(1 + e^(-x))sigmoid 函数将任何实值数映射到 0 和 1 之间的范围当 x 接近正无穷大时,sigma(x) 接近 1,当 x 接近负无穷大时,sigma(x) 接近 0。
曲线的中点,其中 sigma(0) = 1/2 at x = 0优势 - 用于二元分类模型的输出层,其目标是产生输入属于特定类的概率它将输入值压缩到所需的范围,使其适用于需要二元决策的任务缺点 -sigmoid 函数是,对于极端输入值,其输出饱和(变得非常接近 0 或 1),这可能导致深度神经网络反向传播过程中的“梯度消失”问题。
2. 双曲正切函数 (tanh):
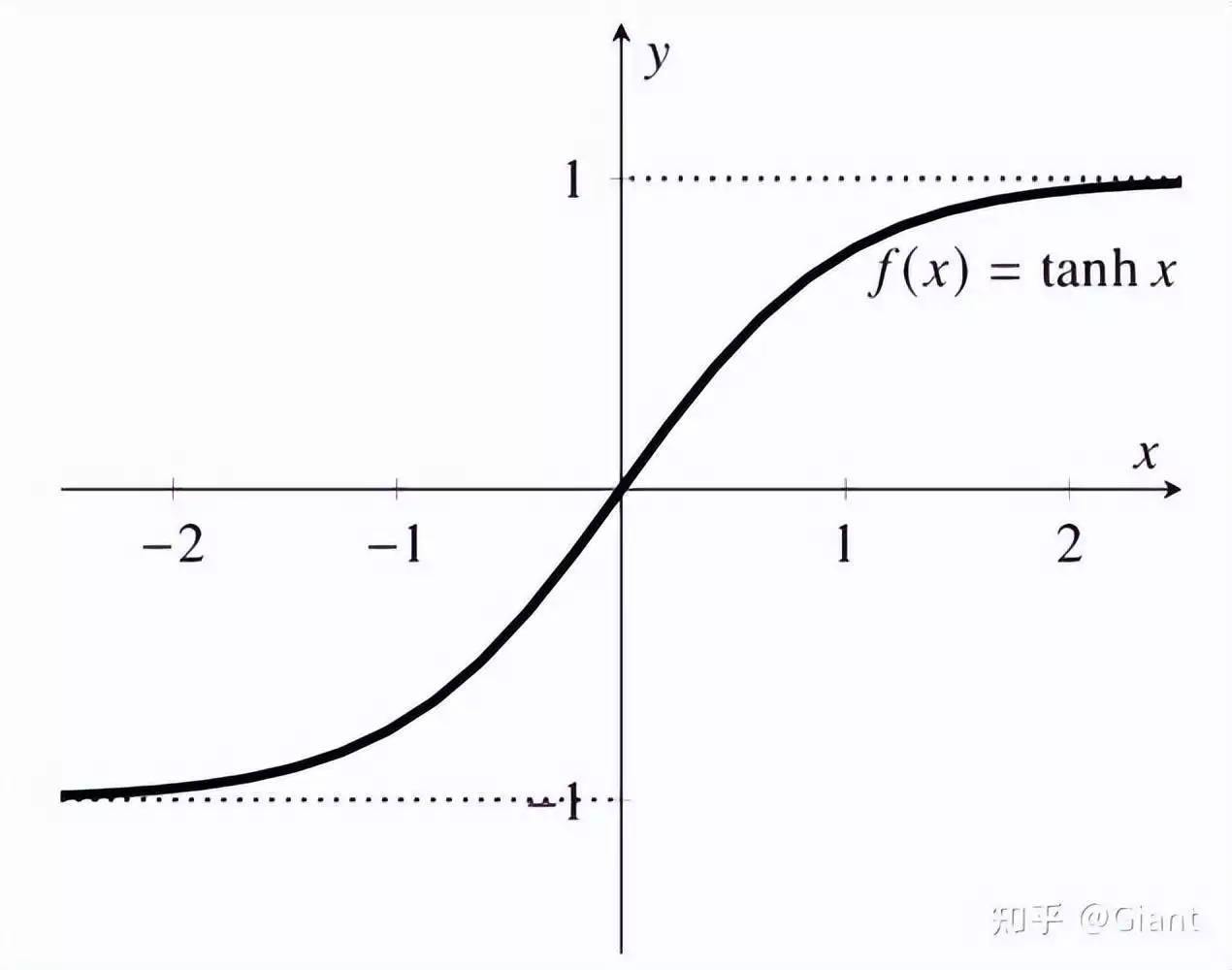
双曲正切函数 (tanh) 是双曲正弦函数的重新缩放版本,由以下公式定义:tanh(x) = (e^(2x)— 1)/(e^(2x) + 1)tanh 函数将任何实值数映射到 -1 和 1 之间的范围当 x 接近正无穷大时,tanh(x) 接近 1,当 x 接近负无穷大时,tanh(x) 接近 -1。
曲线的中点,其中 tanh(0) = 0,位于 x = 0优点:tanh函数具有零居目的优点缺点:对于非常大或非常小的输入,都会遇到梯度消失问题。3. 整流线性单元 (ReLU):
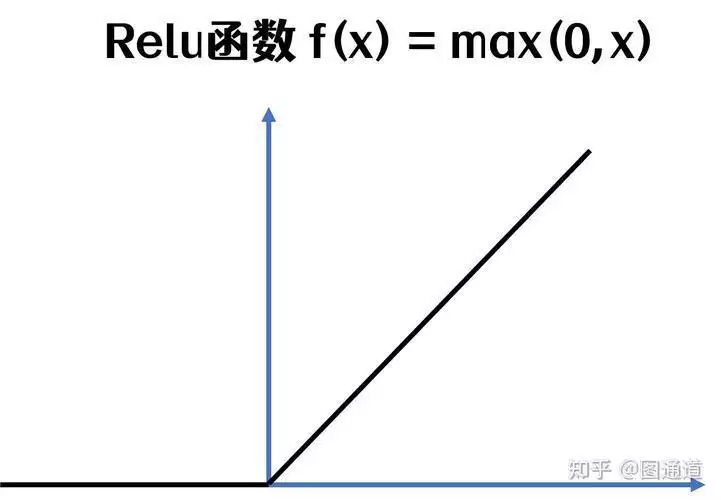
ReLU 代表整流线性单元,是人工神经网络中使用的一种流行的激活函数ReLU 函数定义为:ReLU(x) = max(0, x)换句话说,如果输入 x 为正,则输出等于 x,如果输入为负,则输出为零该函数为模型引入了非线性,并且计算效率很高。
优势-ReLU 激活简单且计算高效,仅涉及阈值操作因此,收敛速度要快得多2. 它不会在 Sigmoid 和 tanh 等正区域饱和3. ReLU 会导致网络中的稀疏性,因为某些神经元可以对某些输入输出零,从而有效地减少了活跃神经元的数量。
缺点:具有ReLU激活的神经元有时会在训练过程中变得“死亡”,这意味着它们对任何输入的输出总是为零如果一个大梯度流过 ReLU 神经元,导致权重以神经元始终输出零的方式更新,就会发生这种情况它被称为垂死的ReLU问题。
为了解决这个问题,已经提出了 Leaky ReLU 和 Parametric ReLU 等变体ReLU 的流行变体包括:LeakReLU:LeakReLU(x) = max(α*x, x) [通常 α = 0.01]其中 alpha (α) 是一个小的正常数,通常接近于零。
旨在解决“垂死的 ReLU”问题2. 参数化 ReLU (PReLU):f ( x ) = max(αx, x )其中α 是可学习的参数3. 指数线性单位 (ELU):ELU (x) = x 如果 x > 0。
如果 x< = 0,则 ELU (x)=α(e^x — 1)— ReLU 的平滑版本,允许负值,但惩罚很小— 旨在缓解渐变消失的问题4. Softmax 分类器:它以实数向量为输入,并将它们转换为多个类的概率分布。
softmax 函数定义如下:
softmax 函数对输入向量的每个元素进行幂化,并通过所有幂值的总和对结果进行归一化这种归一化可确保输出向量的总和为 1,使其可解释为概率优势:1. softmax 函数的输出表示类的概率分布输出向量的每个元素都表示输入属于相应类的概率。
2. softmax函数对输入值的大小很敏感输入值越大,指数值越大,概率越高3. softmax函数是可微分的,这对于使用基于梯度的优化算法训练神经网络至关重要4. softmax 函数通常用于神经网络的最后一层,用于涉及多个类的任务,例如图像分类或自然语言处理。
它有助于将原始输出分数 (logits) 转换为概率,从而促进多类场景中的决策这些激活函数用于不同的目的,可能适用于特定类型的问题或网络架构激活函数的选择取决于问题的性质、数据类型和所用网络的特性等因素。
